This is a cross-post about database diagrams, originally a self-answered question on the new Software Recommendations Stack Exchange site.
Up until a few years ago I used Microsoft Visio to reverse engineer an existing database to a diagram. This feature has been deprecated for a while now, and I’m rather stuck in finding an alternative.
Requirements
So, what would be the requirements for an alternative? Most of the requirements below were in Visio, though not all of them. I guess finding one piece of software that has them all is not feasible, but I’d like to get close.
Important:
- SQL Server 2012 databases;
- Reverse engineer tables with all columns and Primary/Foreign Key indications;
- Reverse engineer foreign keys as connectors between tables;
- Manual layouting of boxes and connectors (I want to group stuff visually);
- Basic theming: choose background colors for tables;
- Able to handle complex models, e.g. 100+ tables;
- Able to choose which items to show or not (e.g. leave out certain tables, etc);
- At least a free trial available;
- Exporting to various formats for distributing and printing purposes, PDF, or PNG would also do;
- WYSIWYG;
Main bonus points:
- Runs on Windows 8 (though I’d install a Linux VM for software fulfilling all important requirements)
- Automatic layouting and connector routing to minimize overlap;
- Able to do SQL Server 2008 and 2008R2;
- Able to reverse engineer views;
- Free (or a free version);
- Incremental update, e.g. reverse engineer again and have tables added/removed, etc., whilst keeping theme, existing layout, etc.
- Pretty diagrams (modern look and feel, anti-aliasing, choice of fonts, colors, gradients, drop shadows, theming, etc);
- Friendly learning curve (I can handle many complex features as long as it’s easy to get the basics done quickly);
MUST HAVE:
- Installer doesn’t secretly install toolbars in my browser or change my home page!
My Research
Of course this question has been asked before, even on sister sites (with some success even though they’re off topic there). Here’s a few:
And slightly similar, from DBA.SE:
Furthermore, Wikipedia has a table comparing several software packages for “reverse engineering” feature:
Tried
These are the things I’ve tried:
- Visio 2003 (this is what I used to use). Not free, outdated, but otherwise it fit the bill for most points. Not an option anymore though.
- Visio 2010 and 2013 (this is what I have currently). Reverse engineering is no longer supported. I’ve considered writing a plugin or using VBA to hack things together though. Not sure how tough that would be. It’s not free (except I guess that I personally have it already), but fits the bill on a lot of other points.
- Graphviz. Tried this quite some time ago, from what I remember it had a bit steep learning curve and I wasn’t quite able to manually determine final layout.
- SSMS diagrams. This works for small cases, but can be cumbersome for larger cases.
- Visual Studio 2012 ADO.NET Entity Data Model. Manual layouting of connectors is limited, theming does not exist at all, it is really meant for a goal other than documentation and it shows (e.g. default you get “Navigation Properties”, etc), and it doesn’t work well for 100+ tables. This may be useful for smaller scenario’s but doesn’t fit the bill for me.
And I think I may have tried a few suggestions from the SO threads, though I can’t really remember specifics.
So I asked: what would others recommend?
…Radio silence…
So I guess I’ll have to answer my own question then. My suggestion:
Use plain Visio for this.
Here’s why.
Explanation of my approach
There is no tool that conveniently satisfies all mentioned requirements, not even one that fulfills the main requirements only. Visual Studio 2012 comes close, but lacks theming support and didn’t work very well for a large number of tables.
The following process worked for me:
- Create a blank Visio Flowchart template. I’ve also tried the UML template and shapes but this has infuriating behavior for connector routing. Not recommended! Choose a design you like. Set the page and print sizes to something you want (I chose landscape A3 format and the “Linear” theme).
- Open a query in SSMS on the side to get the details you’ll need later: tables, column names, and IS NULL info.
|
|
SELECT t.name TableName, c.name ColumnName, CASE WHEN c.is_nullable = 1 THEN '' ELSE 'BOLD' END AS IsNotNullable FROM sys.tables AS t JOIN sys.columns AS c ON t.object_id = c.object_id WHERE c.name NOT IN ('Excluded1', 'Excluded2') ORDER BY t.name, CASE WHEN c.name = t.name + 'Id' THEN 0 WHEN c.name LIKE '%Id' THEN 1 ELSE 2 END, c.column_id |
- Start adding the tables one by one. Choose manually which tables and columns you which to include.
This is an example of what the end result looks like:

Or a zoomed out screenshot of the entire model (because it was manual labor I chose to include significantly less than all 100+ tables):
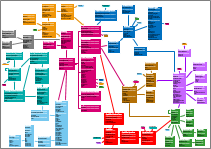
The procedure I used to make the “tables” look as they do:
- Headers are bold and a larger font size.
- Separators aren’t lines but just a series of bold “—” dashes after eachother.
- Four “sections”: TableName, Primary Key, Foreign Keys, plain columns.
- Bold for NOT NULL columns.
- White for TableName and separators, black for column names.
In addition, I chose for foreign keys to:
- Never allow crossing connectors, and instead creating small “reference” blocks that refer to a table that’s somewhere on the other side of the model.
- Not include all tables (i.e. there are more foreign keys than connectors).
Hopefully the above will be of use to others too.
How it holds up to the requirements
As a bottom line, I do recommend this approach, mainly because you end up with a visually appealing model and a high degree of control. This approach doesn’t fit the entire bill though. Here’s how it holds up to the requirements:
Data connectivity
- SQL Server 2012 databases
- Reverse engineer tables with all columns and Primary/Foreign Key indications
- Reverse engineer foreign keys as connectors between tables
± This is all possible but not automated. So “more or less”.
Control and visuals
- Manual layouting, basic theming, able to choose which items to show
- Able to handle complex models, e.g. 100+ tables
✓ Yes, this all works very well with plain Visio.
Moneys
- At least a free trial available
✓ AFAIK there’s a free Office trial available. I haven’t looked into this though as I have Visio.
Other
- Exporting to various formats
- WYSIWYG;
✓ Yes, this is available in Visio.
Bonus Points
It has about half of the bonus points:
- runs on Windows 8
- SQL 2008 also supported
- pretty
- friendly learning curve
Conclusion
It’s a shame I didn’t find any tool that met my requirements. I actually feel like failing in this regard: surely I haven’t looked hard enough?
It’s also a shame that I wasn’t able to muster the perseverance to automate this. I’m a developer for fuck’s sake!? (Or am I?)
It’s without shame though that I did end up with a rather pretty, useful diagram, with exactly the layout and content I wanted. I guess “Good is the enemy of Perfect” held up here.