Reusing a properly modelled domain for storing data in Elasticsearch does not work well out of the box. Let’s examine a problem scenario. Consider this mini-domain:

This ties in with my last post, where I mentioned that loops are a pain for serializing to json. Here’s the loop, visualized:
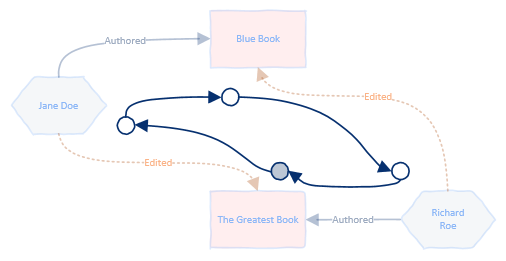
The problem is that NewtonSoft (used under the hood by Nest) will start serializing “The Greatest Book”, and recurses through all properties. In the end it’ll try to serialize “The Greatest Book” again as part of “Richard Roe”‘s AuthoredBooks property.
Breaking this serialization loop is actually pretty simple with NewtonSoft, and since a while you can inject the appropriate NewtonSoft setting in Nest as well. Something like this:
|
1 2 3 4 5 |
return new ConnectionSettings(new Uri("http://localhost:9200")) .SetJsonSerializerSettingsModifier(m => { m.ReferenceLoopHandling = ReferenceLoopHandling.Ignore; }); |
Problem solved, right? Not so much. Here’s why. Suppose I use the LoopHandling “fix” and load up the mini-domain with this integration test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[Explicit][Test] public void Drop_and_recreate_filled_books_index() { NestUtil.Client.Value.DeleteIndex(i => i.Index(indexName)); // Ignore result. NestUtil.Client.Value.CreateIndex(i => i.Index(indexName)); var johndoe = new Person { Id = 2001, FirstName = "Joh", Surname = "Doe", }; var richardroe = new Person { Id = 2002, FirstName = "Richard", Surname = "Roe", }; var janedoe = new Person { Id = 2003, FirstName = "Jane", Surname = "Doe",}; var thegreatestbook = new Book { Id = 1001, Title = "The Greatest Book", }; var whitebook = new Book { Id = 1002, Title = "Little White Book", }; var bluebook = new Book { Id = 1003, Title = "Blue Book", }; thegreatestbook.AddAuthor(johndoe); thegreatestbook.AddAuthor(richardroe); thegreatestbook.AddEditor(janedoe); whitebook.AddAuthor(johndoe); whitebook.AddEditor(richardroe); bluebook.AddAuthor(janedoe); bluebook.AddTranslator(richardroe); bluebook.AddEditor(richardroe); NestUtil.Client.Value.Index(thegreatestbook, i => i.Index(indexName)); } |
This will create a document in Elasticsearch of a whopping 71 KB / 1364 lines, see this example JSON file. Not so good.
The simple solution which would do for now would be to index only Book items, and all related people (authors, editors, translators), but not those people’s Books (AuthoredBooks, etc). We somehow need to let Nest and Elasticsearch know that we want to stop recursion right there. The question is how to be explicit about how they should map my domain objects to documents. I see two courses of action I like:
- Declarative mapping, with Attributes. This would (to my taste) require separate DTO classes to represent the documents in Elasticsearch, and have an explicit transformation between those DTO’s and my Domain objects. (I wouldn’t like to litter my domain object classes with persistence-specific attributes.)
- Mapping by code. This would seemingly allow me to keep using domain object classes for persistance, having the “Mappings” in code as a strategy for the transformation in separate files. At this point though I’m unsure if this approach will “hold up” once you start adding more complex properties and logic to domain objects.
I lean towards option 1, even though it feels like it’ll be more work. Guess there’s only one way to find out…