Getting to the .NET Core of things
This post aims to help developers from other tech stacks get up to speed with .NET Core. It should be enough to follow further discussions of this tech stack, as well as help you decide whether it’s something you might want to investigate further.
Introduction
Microsoft’s tech stack (for various types of applications) has been .NET for over 15 years now. For the most part of those 15 years, Microsoft has exclusively focussed on proprietary, Windows-only software. In recent years Microsoft shifted to open source and cross platform solutions in many areas, including .NET. With that, the newest incarnation of .NET is .NET Core, which is completely open source and available across various platforms.
This post explains the state of Microsoft’s tech stack, from the perspective of this new “.NET Core”.
Note on versions: this post was written when .NET Standard 2.0 and .NET Core 2.0 have just come out. Most information also holds for earlier versions, but unless specified otherwise, all text and code below assume version 2.0 to be the context.
How .NET traditionally worked
Let’s first investigate how .NET in general works, with the pre-.NET Core context in mind.
As a developer, you can write some C# or VB.NET code. When you compile this code, you’ll get IL (Intermediate Language), which is bytecode. This bytecode is packaged in DLL and possibly EXE files, which runs on any computer. Well, technically it runs on any computer… that has the .NET Framework to run it. Remember, talking pre-.NET Core here, so this “any computer” has to be a Windows machine with the proper version of the .NET Framework.
The part of .NET that actually runs the application is the CLR (Common Language Runtime). Included with the CLR is a GC (Garbage Collector) and other memory management tools. Another important part of the .NET Framework is the BCL (Base Class Library) which contains essential base libs, for example for collections, IO, XML handling, etc.
In addition, .NET itself also used to ship with application frameworks. For example frameworks for desktop applications (WinForms and WPF), as well as web application frameworks (ASP.NET). This has changed in recent years. Now, almost all application frameworks (including ASP.NET MVC), are distributed as packages. This is done using the NuGet package manager, where application frameworks live as siblings to other libraries and SDKs. Note that Microsoft’s packages sit there along the third party packages.
And that’s all the basics for building .NET applications traditionally. With that out of the way, let’s move on to the interesting bits.
Terminology
The best way to start explaining about the “new” .NET situation is by building a glossary.
Terminology around .NET Core has been very confusing for quite some time. But since around halfway through 2017 it seems things are coming together. I’ve left all obsolete terms (Hello there, “DNX”!) for an appendix at the end, and will first focus on current terminology. Here’s a quick overview of the important terms.
Let’s start with the most important thing, which is in my opinion is not “.NET Core”. It is .NET Standard, which simply specifies an API. It lists all the (namespaced) types and methods you should implement to create a .NET Implementation (sometimes also referred to as a “.NET Framework” or a “.NET Platform”).
So what .NET Implementations are there then? Several! First, the most well-known one is the .NET Framework, which is available only for Windows.
Second, the .NET Framework framework has been ported, and this (cross platform) port is known as the Mono framework. Today Mono is not only port, but it is in fact also explicitly a .NET Implementation by implementing the .NET Standard officially.
Third, there’s Xamarin. Now there is a company named “Xamarin” (now owned by Microsoft), which develops similarly named platforms: Xamarin.iOS and Xamarin.Android.
These are both versions of Mono for their respective mobile platforms. Recent and upcoming versions of Xamarin.iOS and Xamarin.Android will be .NET Implementations that conform to the .NET Standard too.
Fourth and finally, let’s get to the main topic: .NET Core. This is a cross-platform .NET Implementation by Microsoft, conforming to the .NET Standard. Moreover, it’s completely open source, with most parts using the permissive MIT license.
Basically Microsoft re-implemented the Windows-only .NET Framework in the cross-platform .NET Core, where overlap between the two is specified by .NET Standard. Note that large parts of .NET Core are forked from the .NET Framework.
Within .NET Core there are two other important terms. First, CoreCLR is the Common Language Runtime (CLR) of .NET Core. This is the part that runs your .NET Core applications, takes care of memory management, etc. Second, CoreFX is the Base Class Library (BCL) of .NET Core. It contains the basic types such as those around collections, IO, xml handling, etc. All of these bits and pieces are available cross-platform.
With those terms laid out, let’s dive into the details.
.NET Standard
The .NET Standard API specification for .NET Implementations has different versions. The code and documentation can be found on GitHub, which also shows which implementations conform to each version of .NET Standard. Here’s a trimmed down version of the current overview:
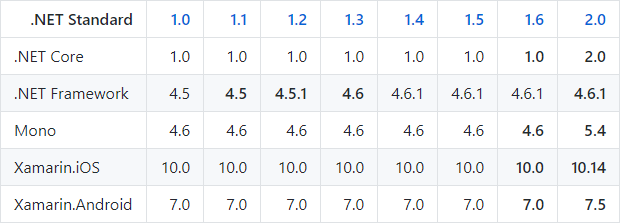
For example, from the above you can tell that .NET Core 1.0 implements .NET Standard 1.0 through 1.6. And as another example, .NET Standard 2.0 is implemented by both .NET Core 2.0 and .NET Framework (the Windows-only one) 4.6.1.
You can easily check what’s in a specific version by checking the markdown-based docs for all versions. It includes “diff” files showing what changed since the previous version. For example, this API was added to .NET Standard going from 1.6 to 2.0:
|
|
namespace System { + public sealed class StackOverflowException : SystemException { + public StackOverflowException(); + public StackOverflowException(string message); + public StackOverflowException(string message, Exception innerException); + } } |
Now for the important part! When writing .NET code, you can choose what your intended target (“Target Framework“) is. But this does not need to be a .NET Implementation.
You can also target .NET Standard!
But “Why would you target a spec, which cannot run anything?”, you might ask. The main reason to do that would be when you’re writing some kind of library.
For example, suppose you’re targeting .NET Standard 2.0 with your hip new FooBar library. By using .NET Standard as a Target Framework you’re basically saying: anyone running an app on a .NET Implementation supporting .NET Standard 2.0 can use my library.
Now suppose you are a library or framework author who publishes things on NuGet. You then have to specify what Target Framework your code’s compatible with. So from NuGet we can extract interesting statistics, and see that the community is really getting on the .NET Standard bandwagon. Most popular libraries already support even from some 1.x version onward of .NET Standard (usually 1.3 or 1.6).
In addition to explicit Framework targeting, there’s something specific for .NET Standard 2.0. A “compatability shim” was also rolled out in the tooling around packages, meaning you can use any library that is de facto API-compatible with .NET Standard 2.0. Even if the author didn’t explicitly declare it to be compatible. And although this might seem dangerous, it works pretty well in practice, allowing for application authors to switch more quickly to .NET Core if they want to.
.NET Core
This is where things get cross-platform! You can download the SDK for Windows, various Linux distributions (e.g. RHEL, Ubuntu and Mint, SUSE), and Mac OSX. The SDK contains both the CoreCLR (runtime) to run applications, as well as the tools needed to create and build applications.
After installing you can use the command line interface to test everything is working. Just:
- Create a folder “
hellow” and cd into it;
- Execute
dotnet new console, which generates:
|
|
namespace hellow { class Program { static void Main(string[] args) { Console.WriteLine("Hello World!"); } } } |
- Execute
dotnet run;
And you should see the traditional “Hello World!” greeting now.
To move beyond the CLI to using an IDE for development, there are several choices.
- Visual Studio is still probably the best experience on a Windows machine.
- VS Code is available on Windows, Mac, and Linux, offering a pretty light-weight IDE.
- JetBrains Rider is an Intellij-like IDE for .NET development, available on Windows, Mac, and Linux.
Any code you compile, on any OS, with any IDE, should be runnable on .NET Core on other OSes. If .NET Core is installed on that OS.
You can also create “self-contained applications”: applications that include the .NET Core runtime as well. Obviously, then you need to specify the platform to target because .NET Core binaries are platform-specific. You do this by publishing with a Runtime Identifier (RID) like “win10-x64“, or “osx.10.12-x64“, or “linux-x64“. This will compile your .NET Core application and bundle it with the appropriate version of .NET Core itself.
And that’s really all there is to it. From here on out it’s all about writing code in a .NET language of your choice. This means C# or F#, or VB.NET in the near future.
Wrapping Up
Microsoft is changing up their game. Although the traditional .NET Framework is here to stay, the new .NET Core framework is the future. They are both .NET Implementations and yes: they have overlap (as defined by .NET Standard). But you can safely bet on the fact that .NET Core and .NET Standard are going to get focus forward.
Given that all these efforts are both open source and cross-platform, riding along that train seems like an excellent idea. Especially if you’re currently using another tech stack, but interested in the .NET ecosystem, now is a great time to hop on and join for the ride!
Just give it a go!
~
This post formed the backbone of my talk at DomCode 2017-08-29. By and large it can be considered a transcript of that talk. If you want you can also download the slides of my presentation.
Appendix A: Bonus Topics
There are plenty more in-depth and advanced topics. Here’s a quick list of particularly interesting ones you could further pursue:
- Docker and .NET Core go very well together. The official docs on that should be a good starting point.
- EF Core (Entity Framework Core) gets a lot of attention too. EF is Microsoft’s ORM framework, and it has its own dedicated (sub)site with more info.
- UWP (Universal Windows Platform) for creating Windows Store apps that could be cross platform (including things like Xbox, Windows Phone, HoloLens, etc) will also likely conform to .NET Standard. Check the main UWP docs for further info.
- Roslyn is the code name for the open-source compilers for .NET languages. The best starting point for more details is the Roslyn Github repo.
- .NET Native will allow you to compile your .NET code not to IL (bytecode), but to platform-specific native code. Check the official docs for more info.
Appendix B: Obsolete Terminology
Here’s a short list of (currently) prominent terms that I consider to be obsolete, along with their definition (and the source of that definition, if applicable).
- DNX (Dotnet Execution Runtime), DNVM (script for obtaining DNX) and DNU (Dotnet Developer Utility) were part of older Release Candidates of .NET Core. The features have mostly been moved to the .NET Core CLI. See the Microsoft docs for more info.
- project.json was meant to be the new project system, but instead Microsoft decided to move back to csproj files with some new features. Read more on these Microsoft docs pages.
- PCL (Portable Class Library) was an earlier attempt to help library authors create code that could be reused across various fameworks and platforms. The best reference I could find is these docs from Microsoft. In light of .NET Core you can easily forget about it though, unless you need to convert a PCL project to .NET Core.
- vNext (which at some point was also called ASP.NET 5) can best be seen as a working title of the next .NET Framework version (the one for Windows only), but has been dropped entirely. About the only semi-sensible reference left is on Stack Overflow.
- ASP Classic is not really an obsolete term, but rather obsolete technology. The latest stable release was from around the year 2000. It has nothing to do with .NET or the various ASP.NET application frameworks. Wikipedia has a quick history recap if you want it.
References