I’m calling it. Bieb is now officially wrapped up.
I’ve accomplished the bare minimum I set out to do with Bieb, and learned a lot of extra things along the way. But motivation to continue any further has dropped to near zero. And I’m okay with that.
Fair warning: this is a long post. Consider the above to be the TLDR version, and whatever’s below as a peek into my personal notes and thoughts. Read on at your own risk!
…
Still here? Allright, here goes.
Conclusion
So let’s start up with a preliminary conclusion annex Table of Contents:
- Bieb was a fun project. Now it’s “wrapped up” / abandoned.
Azure sucks I disliked working with Azure for a hobby project. Great tech, but that learning curve…- Proper errors in ASP.NET MVC are hard.
- ASP.NET MVC is a nice framework in general though.
- Database integration tests for NHibernate are useful and easy to set up.
- Bieb is a successfull TDD experiment.
- Razor is great for static content. You need nearly zero JavaScript for views.
- Designing (the domain logic for) an entire application is fun!
You want more details you say!? You shall have them! Moving on…
Elevator Pitch
First up, the elevator pitch. There actually was something of the kind (though not in typical pitch-format) on the project home page:
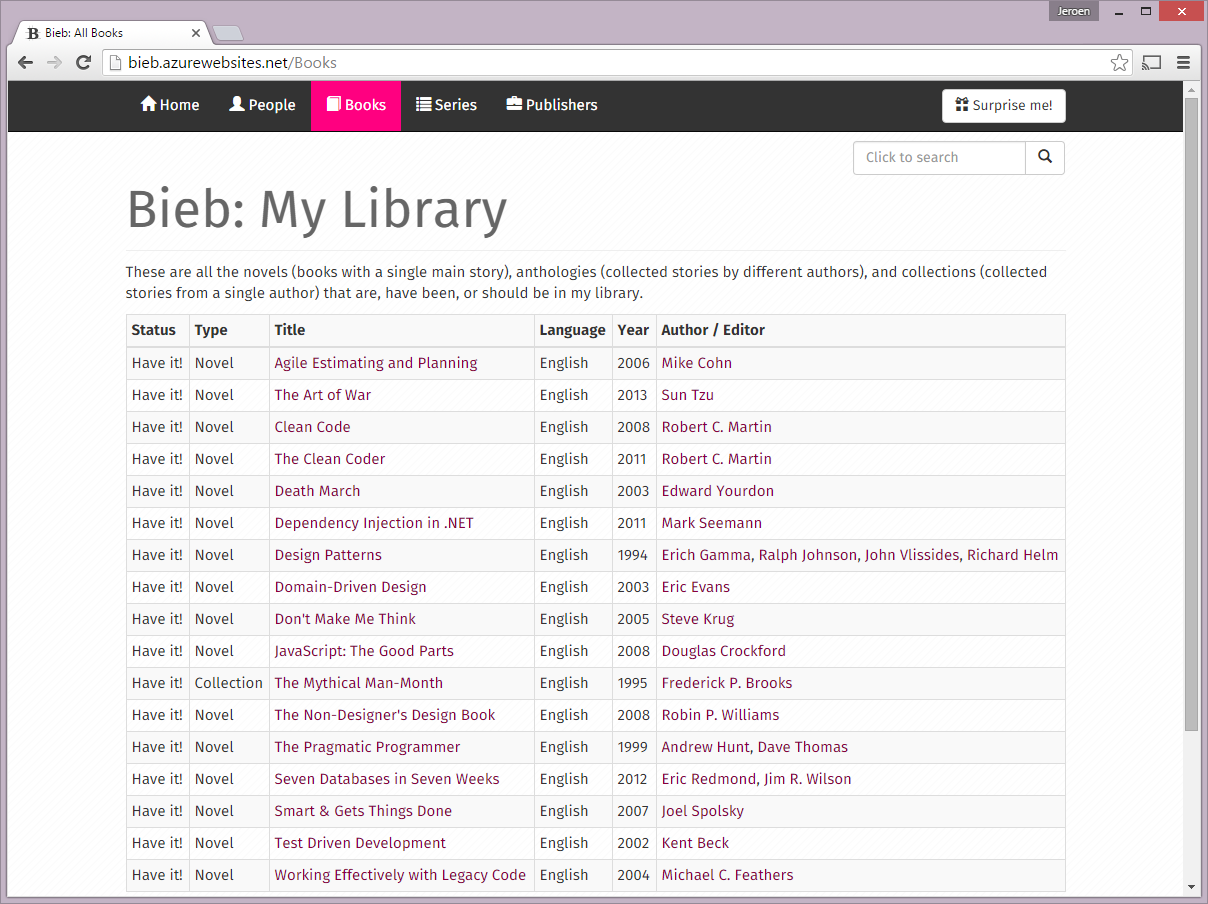
Website project based on ASP.NET MVC for managing and displaying your personal book collection on the web.
At the bottom of the page, the (equally important) secondary objectives are mentioned:
- Finding out more about Codeplex
- Experimentation sandbox for MSSQL, ASP.NET MVC, NHibernate, Ninject, html5, css3, jQuery, and Modernizr
- Experimentation sandbox for trying out competing and additional frameworks
- Having this website project available for anyone who’s interested
- Real-life events such as BBQ’s and drinks to “discuss the project”
And that was actually pretty close to what it turned out to be.
Note that Bieb is not solving a new problem, nor is it solving a problem in new ways. There’s GoodReads, which is a great site that does 90% what Bieb does and more. Bieb was not meant for us to get rich with a “next big thing”; it was meant as a fun project to toy with technology.
The Negatives
Before I get to the positive things about this project, first some negatives.
Azure is no friend of mine
Bieb had to be a replacement for a version of this app I’d hacked together in PHP. With PHP however, it’s very easy and cheap to get some hosting, and very easy to set up a deployment. With .NET, there is no such luxury. Private / shared hosting of .NET sites is expensive. The best option seemed to be Azure (as I had a MSDN subscription that comes along with some Azure credits), but Azure has a very steep learning curve compared to getting a PHP site up and running.
Put in another way: Azure feels solid, but it also feels big and “enterprisey”. There’s just so many buttons and settings and “thingies” that it feels impossible to get started. Watching tutorials doesn’t help much, because your choices are (a) a very specific 20 min tutorial that doesn’t cover all your needs or (b) watching a 6-hour Pluralsight course and still being covered only 80% of the way. Add to that the fact that it’s still under heavy development (which mostly is a good thing, but doesn’t make the learning curve any better), and you’re set up for frustration.
One particular anecdote worth mentioning is as follows:
- I tweeted that I found it confusing that one Azure portal redirects me to yet another Azure portal.
- Azure support tweets back redirecting me to MSDN forums.
- In the forum thread, I get redirected to yet another forum where I should post my findings.
I think I would now like to redirect Azure to a place where the sun don’t shine.
Don’t get me wrong though: I love .NET development and Windows hosting in general. Both Azure and hosting yourself are fine options for business-type projects. However, I’m deeply disappointed in using Azure and .NET for web hobby projects. It’s probably the main reason I’m abandoning wrapping up Bieb, and the main reason I’ll be focussing on other tech for hobby projects in the near future.
Great error pages with MVC are hard
A very specific “negative”, but one that annoyed me to no end. I think I’ve tried to attack this problem 5 times over, and failed every single time.
This is what I wanted to accomplish:
- No YSODs. Ever. Making sure that if your app fails it does so elegantly is very important IMHO.
- Proper HTTP status codes. That means 404s for non-existent static resources, MVC routes that can’t be resolved, but also “semantic” 404s for when a domain item (e.g. a “Book” or an “Author”) was not found.
- A nice error page. That means a proper MVC page when possible, one that gives options (like a Search partial view) and relevant info. Failing that, a nice, styled static html page.
- Proper error logging. The logging and error handling code should be unobtrusive to the business logic. If a request fails (i.e. a 500 error) it should be caught, logged, and the user should be directed to a meaningful, useful page with proper content but (again) also a proper HTTP status code.
Whenever I tried to tackle these requirements, I would fail to do so, and clicking through the online resources about this problem I would inevitably end up at Ben Foster’s blog post on this problem. That excellent post notwithstanding, I have never gotten this to work on IIS or IIS Express.
And having failed to get this working locally, I dread the thought of having to get this to work on Azure…
The Positives
There were also many positive aspects about fiddling with Bieb. Here are the main ones.
NHibernate Database Integration Tests
I continued to work on a way to run database integration tests with a unit testing framework, based off an approach we took at my previous job. Here’s what the base test fixture looks like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public abstract class DatabaseIntegrationTest { protected ISession Session; [SetUp] public virtual void SetUp() { if (Session != null && Session.IsOpen) { Session.Close(); } Session = Factory.Instance.OpenSession(); } [TearDown] public void TearDown() { Session.Dispose(); } } |
The Factory has some more bootstrapping code for recreating the database schema from scratch. All this setup allows you to write this kind of test:
|
|
[Test] public void Can_Persist_DoB_From_MiddleAges() { var person = new Person {DateOfBirth = new UncertainDate(1600, 1, 1)}; Session.Save(person); Session.Refresh(person); Assert.That(person.DateOfBirth, Is.EqualTo(new UncertainDate(1600, 1, 1))); } |
Which is a nice way to fix a database issue in a test-driven manner.
Currently my approach has one big flaw though: the tests are not isolated. Each test has to account for previous tests possibly having left data in the database. For the tests written so far that doesn’t matter, but it’s an accident waiting to happen nonetheless.
I see basically two solutions for this:
- Drop and recreate the database before each test. But that’s probably slow.
- Wrap each test in a transaction, and roll it back at the end. But that exludes the option of testing things that require actually committing transactions.
Truth be told, I wrote most database integration tests because I was unsure of how NHibernate would function and/or handle my mappings. And for that (i.e. learning NHibernate) the current set up worked just fine. If I were to continue with Bieb there would most likely come a time where I’d go for option 2. I think Jimmy Bogard typically advocates a similar approach.
PS. For what it’s worth, I’ve written a GitHub Gist with a minimal setup for creating NUnit+NHibernate tests, specifically geared to creating minimal repro’s to share with colleagues or on Stack Overflow.
ASP.NET MVC is a very nice framework
I quite like the kind of code you have to write to get pages to the user with MVC. Here’s an example of a Controller action in Bieb:
|
|
public ActionResult Details(int id) { var item = Repository.GetItem(id); if (item == null) { return PageNotFound(); } var model = ViewEntityModelMapper.ModelFromEntity(item); return View(model); } |
It’s short and to the point as it delegates the other responsibilities to (injected) dependencies like the Mapper and Repository. In addition, Razor views are also pretty easy to write. At the least, they are a breath of fresh air after WebForms.
So, if you want to create web sites with a big C# component, ASP.NET MVC is a fine choice. However, I do ponder if a more SPA-like approach (with Web API or similar + an MV* client side library) or a full-stack JavaScript solution are better choices for new web development projects…
Having said that, I’m very pleased with how Bieb was a great way to learn ASP.NET MVC.
Test-Driven Development
I went to great lengths to stick to TDD development, even when things got ugly. In particular, I’ve had to learn how to deal with several awful dependencies:
- Random
- HttpContext
- HtmlHelper (and all the things it drags along)
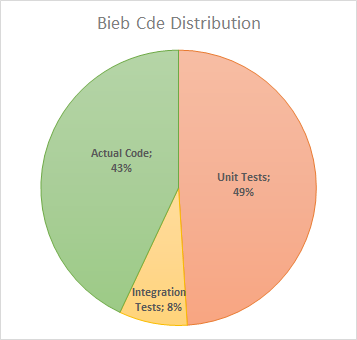
To show the length I went, here’s a summary of the Visual Studio code analysis for LoC:
- 49% (1.564 lines of code) for unit tests
- 8% (253 lines of code) for database tests
- 43% (1.371 lines of code) for all the rest
Even though Lines of Code is hardly ever a good metric (it would be easy to inflate these numbers one way or the other), in this case they do reflect the actual state of the code base. Note that this does not include view code (obviously), nor does it include client side code (there isn’t nearly any; more on that later).
Looking back at the code, I’m also pretty pleased with how the tests turned out. There’s very simple, early tests like this one:
|
|
[Test] public void Can_Add_Story() { var book = new Book(); book.AddStory(new Story()); Assert.That(book.Stories.Any()); } |
As well as tests that border on not being unit tests anymore, but serving IMHO a great purpose:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[Test] public void All_Public_Model_Properties_Have_Display_Attribute() { var model = new T(); foreach (var propertyInfo in model.GetType().GetProperties().Where(RequiresDisplay)) { var hasProperAttribute = false; foreach (var attribute in propertyInfo.CustomAttributes) { if (attribute.AttributeType == typeof(DisplayAttribute) && attribute.NamedArguments != null && attribute.NamedArguments.Count(arg => arg.MemberName == "Name") > 0 && attribute.NamedArguments.Count(arg => arg.MemberName == "ResourceType") > 0) { hasProperAttribute = true; } } Assert.That(hasProperAttribute, string.Format("Missing DisplayAttribute (with reqruied Name and ResourceType arguments) for property [{0}]. Either provided an attribute with localized resource, or exclude this property from needing to do so in the test fixture.", propertyInfo.Name)); } } |
Which tests your haven’t forgotten any attributes like these:
|
|
[Display(Name = "Isbn", Prompt = "IsbnPlaceholder", ResourceType = typeof(BiebResources.BookStrings))] public string Isbn { get; set; } |
Which is worth the fact that it’s not a “clean” AAA-style unit test, in my opinion.
Where’s the client side code!?
But wait a second: where is the JavaScript? The answer: there isn’t (nearly) any! All the custom JavaScript for Bieb is this inline bit of code:
|
|
$(document).ready(function () { $(".fancy-select").select2(); }); |
This may seem silly anno 2015, and truth be told: it is!
Bieb was a vehicle for me to learn mostly server side tech. Most of my hobby projects, as well as the larger part of my day job includes client side programming. I’m confident I could improve Bieb (a lot) with rich client interaction, but haven’t found the need to do so (yet). I was aiming to get a 1.0 release out with mostly MVC code, and work on improved client side components after that.
One important thing to note: I was very pleased with how far you could get with just Razor in creating html. I was also pleased with how much fun it was to generate static content, which Bieb is mostly about.
The admin views of Bieb suffered most from the lack of JavaScript. The UX is bad, at times even terrible. However, with me wrapping up this project that will likely never change.
How are things wrapped up?
So, how are things wrapped up? Well:
- You can check out bieb.azurewebsites.net, at least as long as my free Azure credits last.
- The CodePlex Project will go into hibernation, but will remain available for as long as the wise folks at Microsoft keep it up and running.
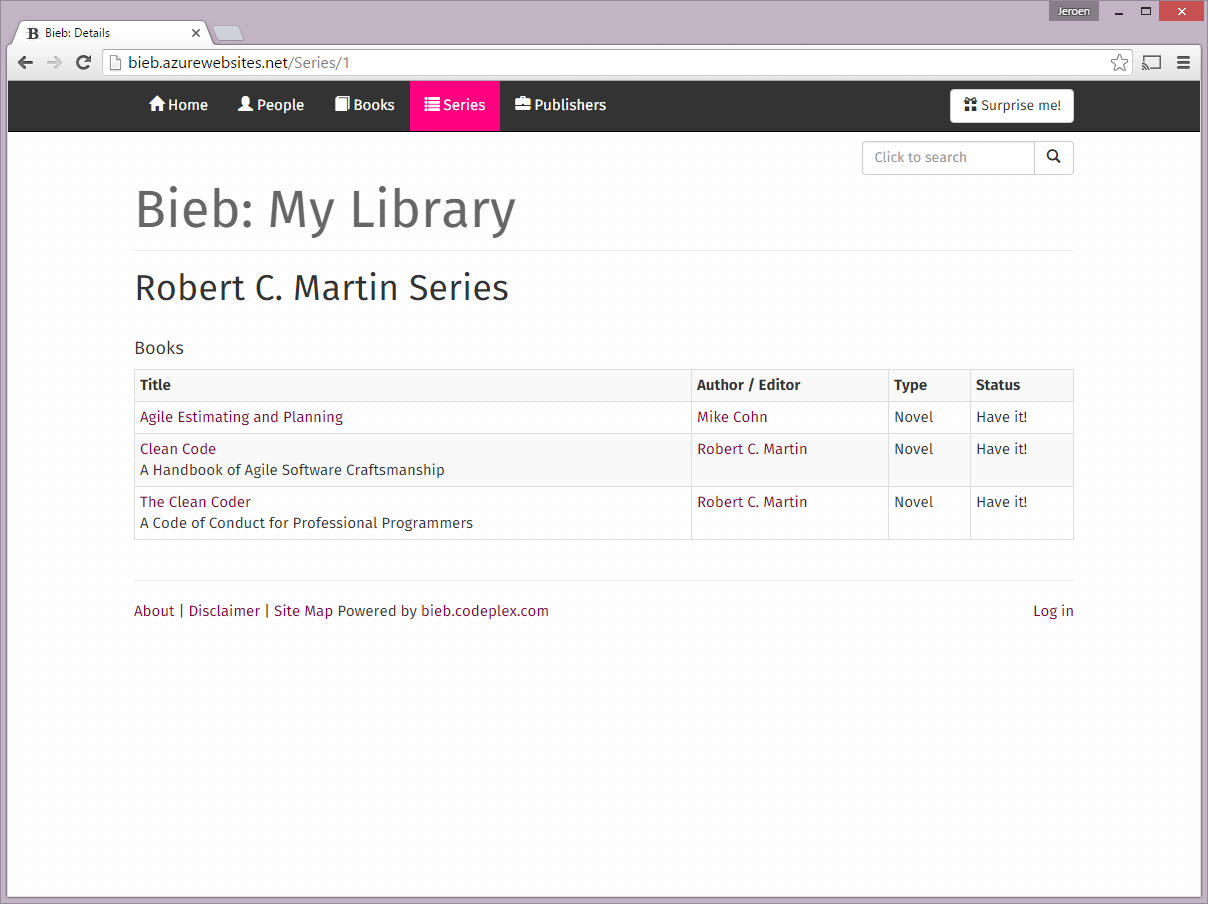
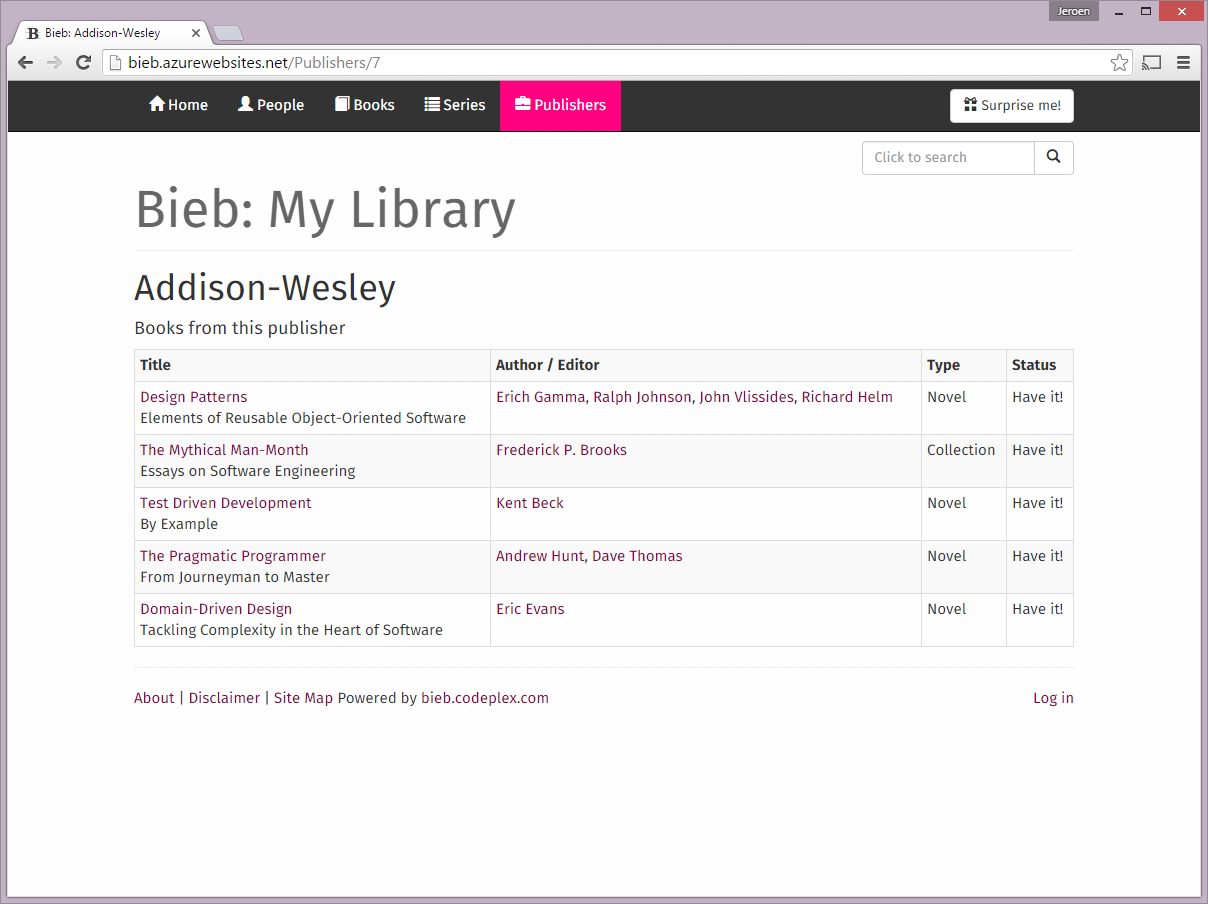
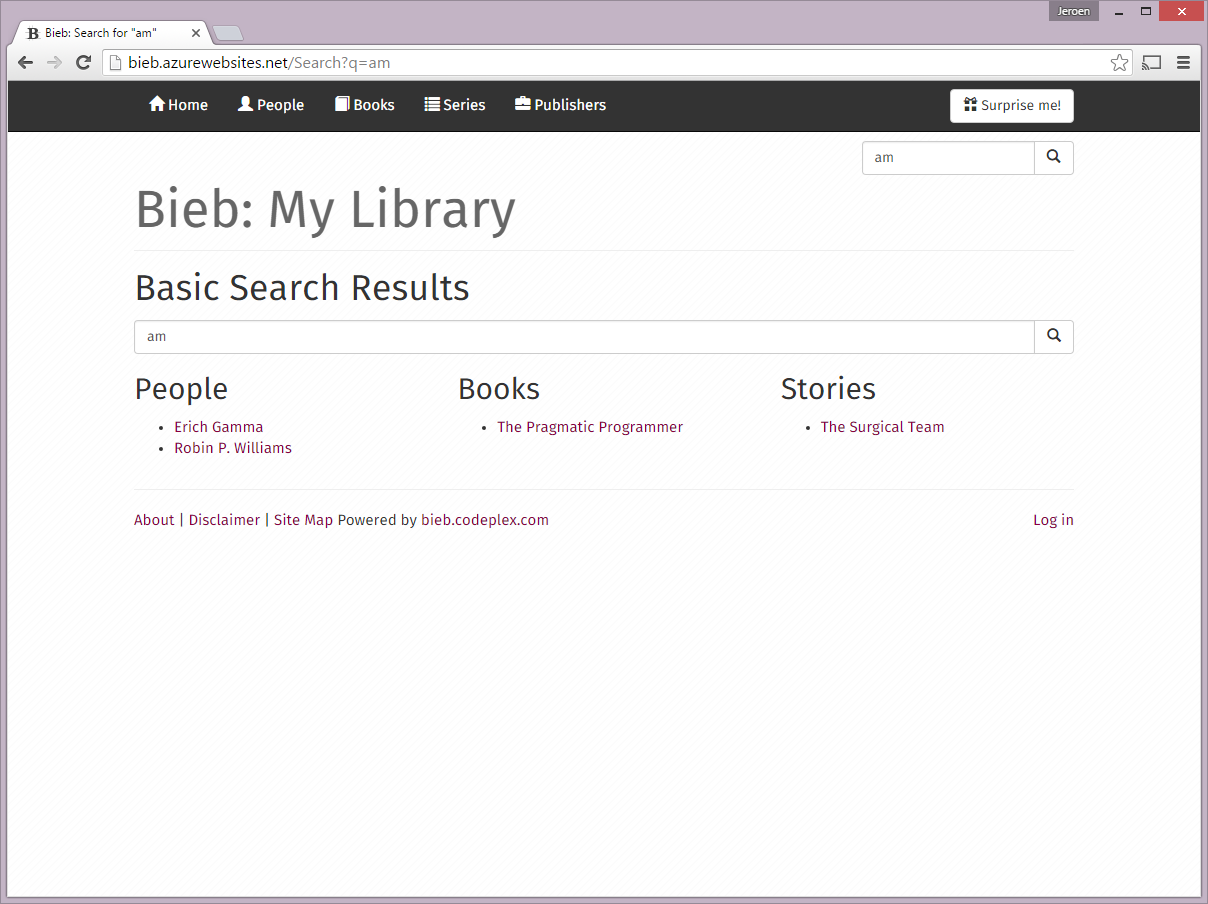
- Some screenshots can be found at the bottom of this post.
And that’s that. Which brings me to say something…
In conclusion
Bieb was a great learning experience. There were things (apart from aforementioned struggle with Azure) I did not really enjoy coding, including:
- Setting up Logging. A real website needs this, but setting it up is a chore. Setting it up so that it’s unobtrusive can even make it a tricky chore.
- Setting up a Dependency Injection Framework. DI itself can be a great help, I find that it kept my code clean and testable by default, but choosing- and learning how to use a specific DI container didn’t feel particularly interesting.
- A proper Unit of Work pattern. It’s necessary, but certainly not my favorite bit of coding. And it probably shows in my codebase, too.
But this is vastly outweighed by the things I did enjoy coding:
- Razor Views were fun to write.
- Designing the Domain and its logic was fun, even though unfortunately sometimes the underlying persistance layer leaks through.
- Project and Solution structure: fun things to think about, even though Bieb is just a small application.
- Routing: it feels good to have nice, pretty URLs.
- Controllers: because I did spend some time on the things I did not like, the controllers did end up looking pretty good.
- Database structure, written through NHibernate mappings that actually is used to generate the database from code.
- Design. Truth be told, the design is at most 49% mine, but that doesn’t make me any less proud of the end result.
Bieb was a fun project to do. I learned a lot. And even though I had many more plans, and even the start of a big backlog, it’s time to move on.
Farewell Bieb, slumber in peace!