Last post I set up five related CSS Katas. The callenge is to recreate a movie poster with just css and minimalistic html. The idea is not to come up with an ultimate and production-ready solution. The idea is to practice, and to think outside the box.
Turns out it takes quite some effort to set aside perfectionism while trying these Kata. Turns out it takes even more effort to publicly post my imperfect attempts. Nonetheless, here goes!
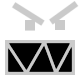
I’ve tried two approaches in reproducing the “Malcolm X” movie poster. Here’s a comparison:

What I noticed immediately while practicing: it does in fact challenge you to think about some basic meta stuff. This particular kata had me stumped with one very basic question: “Is the big ‘X’ semantic, or not?”. That is: is it a drawing shaped like an ‘X’, or is it an actual letter ‘X’? So first thing I considered was changing the actual markup to something like this:
|
1 |
Malcolm XX |
Notice the extra “X” as the main div content.
It’s an option, but it’s a bit too much for me though. It would be as if the poster said “Malcolm X, X”. However, you could say that “:after” the h1 tag comes a big “X” as additional graphical content. This led to Version A:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
* { font-family: Georgia; padding: 0; margin: 0; box-sizing: content-box; } div { position: relative; margin: 20px auto; width: 420px; height: 600px; background-color: black; padding: 10px; } h1 { font-weight: normal; text-align: center; font-size: 22px; color: #EAEAEA; margin-top: 40px; transform : scale(1,1.5); -webkit-transform:scale(1,1.5); /* Safari and Chrome */ -moz-transform:scale(1,1.5); /* Firefox */ -ms-transform:scale(1,1.5); /* IE 9+ */ -o-transform:scale(1,1.5); /* Opera */ } h1:after { content: 'X'; display: block; color: #666; font-size: 650px; font-weight: normal; font-family: Courier New; position: absolute; left: 50%; margin-left: -195px; top: -150px; } |
There’s several things I can notice about this:
- The big X has to be in a certain font. The only widely available font that comes close to the original “X” is the one from “Courier New”, and it’s not all that close. In fact, it looks a lot different.
- It’s pretty tough to control the width of the lines that make up the X. I’m not at all happy about how the top of the “M” isn’t aligned with the top of the big “X”.
- Turns out the “Malcolm X” in the original poster is quite dense. I resorted to using css transforms, but I think there’s also some font-stretching css modules (just haven’t looked into that yet).
- It’s extremely tough to make everything scale nicely. That is, all the various dimensions, font-sizes, paddings, etc. are in absolute pixels. Changing one would mean tweaking all others. I just decided that’s okay for now, allowing me to focus on the other parts of this kata.
- The screenshot was made in Chrome. In other browsers it’s not right at all. I just chose not to focus on browser differences for now.
My other attempt tries to trade semantics for more pixel-perfectness, or at least explore whether that’s a possible path to take. Here’s the code for Version B:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
* { font-family: Georgia; font-weight: normal; font-size: 32px; color: #EAEAEA; padding: 0; margin: 0; } div { z-index: 2; position: relative; margin: 20px auto; width: 420px; height: 600px; background-color: black; padding: 10px 40px; text-align: center; } div:after { content: ' '; -webkit-transform: rotate(55deg); -ms-transform: rotate(55deg); -moz-transform: rotate(55deg); background-color: #666; display: block; width: 640px; height: 30px; position: absolute; top: 300px; left: -60px; } div:before { content: ' '; -webkit-transform: rotate(-55deg); -ms-transform: rotate(-55deg); -moz-transform: rotate(-55deg); background-color: #666; display: block; width: 645px; height: 30px; position: absolute; top: 295px; left: -70px; } h1 { z-index: 3; display: inline-block; background-color: black; margin-top: 20px; padding: 0 5px; } h1:before { content: ' '; z-index: 2; position: absolute; bottom: 558px; right: 40px; top: 35px; left: 40px; border-left: 126px solid #666; border-right: 126px solid #666; } h1:after { content: ' a '; line-height: 1em; font-size: 30px; color: black; position: absolute; bottom: 32px; right: 40px; top: 560px; left: 40px; background-color: black; border-left: 140px solid #666; border-right: 140px solid #666; } |
Here are my notes:
- It looks a lot more like the original than Version A does. Far from perfect, but this direction looks promising.
- This version is equally hard-coded: exact dimensions everywhere, all interdependent.
- There’s some peculiarities about the rotation transforms I haven’t quite grasped yet. For example, the two diagonal bars don’t quite both start equally far from the outer borders.
- After 15 years of CSS, z-indexes still make my head hurt. I need to practice that seperately some time.
All in all I’m quite pleased. Both my solutions look like shit, but hey: it made me practice! I’ll try to charge up, and may even publicize my epic failures for the second Kata as well.













{kind=link}